Data Ingestion and Usage with PersonaFin AI
How is Data Captured?
Personafin AI offers two main methods of capturing user interaction data:
Personafin behaviour capture library
The first capture method is through the Personafin event-tracker library (also known as Web Behaviour Capture library), a light-weight javascript library that can be installed into your user interface to capture interactions with the platform.
This is suited for customers who have an existing UI that they wish to enhance directly with our API’s.
You can read more about how this works, and see installation examples in the Behaviour Capture Getting Started documentation.
iFrame Solution
If you are using our iFrame solution, we use the same library to capture your interactions. However, this is all handled for you within the easy to install components.
This is suited for customers that have an existing UI or platform, or are developing one, that they wish to develop and enhance with minimal effort.
KEY DATA ELEMENTS
An example of data captured (in JSON format) is given on the right. The key elements of this are:
| DATA FIELD | WHY IS IT IMPORTANT? |
|---|---|
| client_key | Lets our data ingestion identify where the data came from and route it appropriately. |
| event_type action | Event type and action performed ensures that the interaction contributes appropriately given its degree of importance |
| event_meta | Event meta contains all important information about the interaction performed. This can include:
|
| related_entities | A list of Tradeable entities associated with the interaction. This is critical for tracking a users entity preferences, and for tracking trending entities. |
| channel_meta.session_id | Allows us to track interactions across a given session. |
| channel_meta.client_ref | A user identifier provided by the customers platform. This is critical to allow us to track a specific users interests and preferences, allowing us to provide a personalized experience. |
// Search type event meta
// Content type event meta
// Meta when interacting with an api output
What happens once interaction events enter our system?
During behaviour capture an interaction event undergoes de-identification and anonymisation, as outlined in here.
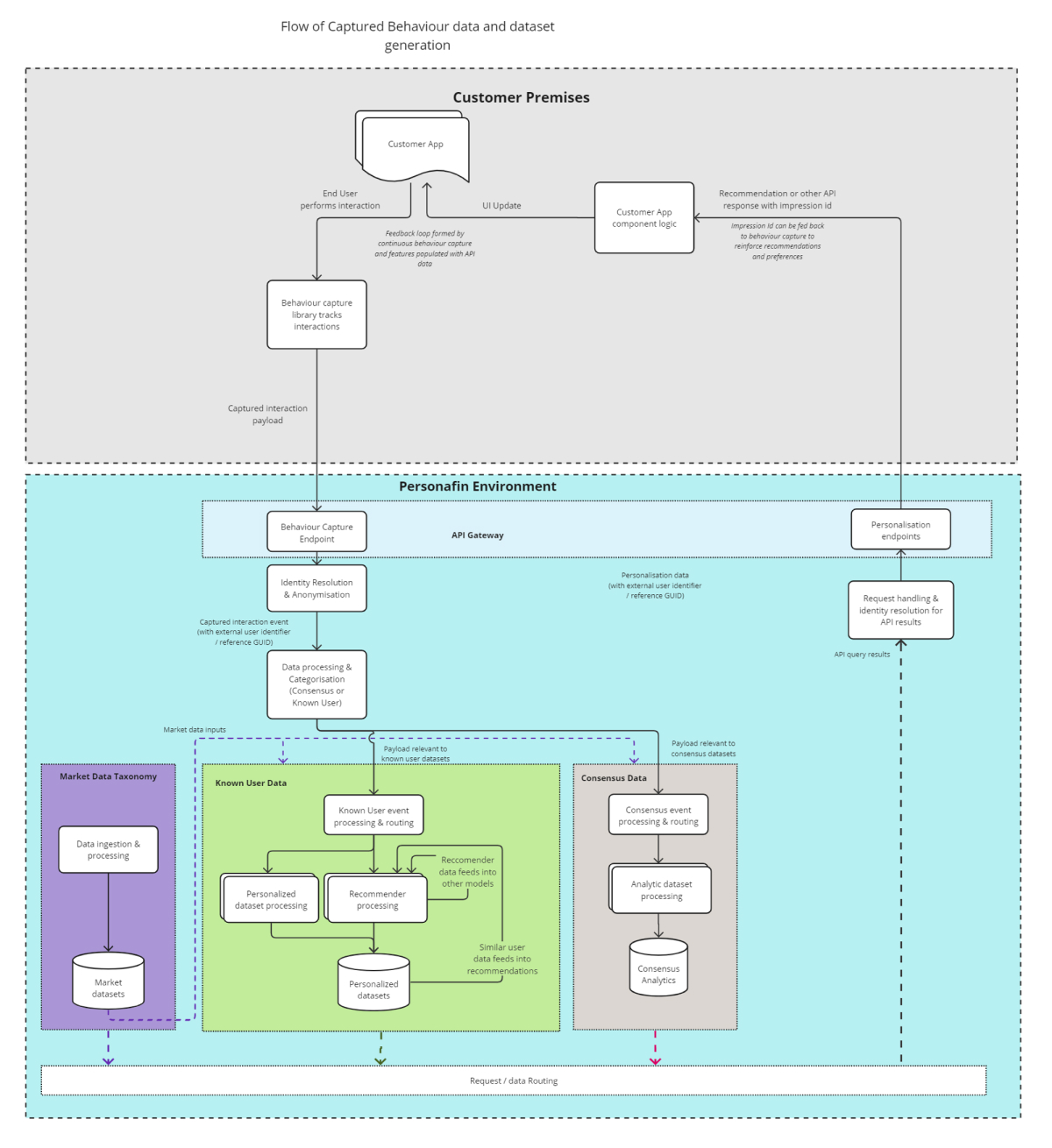
Once the interaction event enters the Personafin environment and has undergone this anonymisation process, it is then processed and routed appropriately for processing various data sets. This includes all consensus data (trending content, search, etc), and datasets personalized for the user that the event was performed by.
These datasets are stored in presentation ready storage ready for API query. At this point all recommended and content items assigned an impression id(known as `impression_id` or `fxcid` for content), which can be surfaced back onto the customer UI ready to be fed back into the behaviour capture library. This allows us to measure recommendation engagement and update the recommenders appropriately.
The example flow below gives a high level overview of the flow of data around the Personafin system.